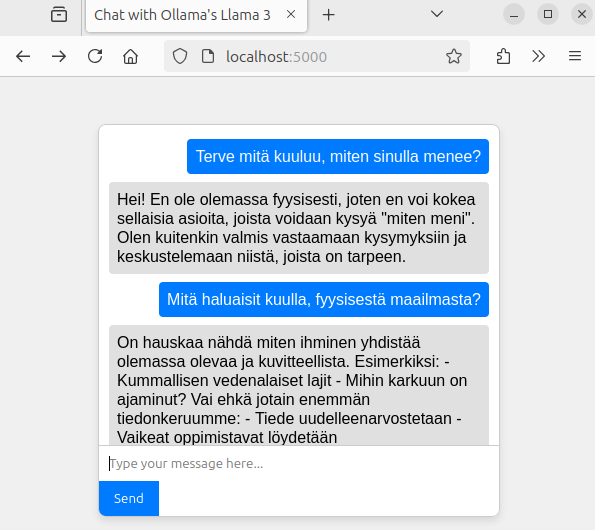
Tehdään hiekkalaatikkoon uusi projekti. Omalla koneella pyörivä web-sivu sovellus, joka välittää viestejä llama tekoälylle ja tulostaa tekoälyn tuottamat viestit omalle web-sivulle.
https://github.com/hennahoo/Oma-tekoaly-NodeJS-lla
Koneelle (hiekkalaatikko virtuaalikoneeseen) asennetaan ensin Llama 3:
sudo su
apt install curl
curl https://ollama.ai/install.sh | sh
# Ladataan Llama 3 tekoälymalleja, jotta voidaan kokeilla niitä:
# 8B model
ollama pull llama3.1:8b
# 70B model
ollama pull llama3.1:70b
# 405B model
ollama pull llama3.1:405b
# Terminaalissa voidaan kokeilla, että LLama 3 toimii, ensin ilman web-sovellusta.
# Basic run command
# (Tämä komento lataa ison 4.9GB mallin, lataus kestää jonkin aikaa...)
ollama run llama3.1
# Specific model versions
ollama run llama3.1:8b
ollama run llama3.1:70b
ollama run llama3.1:405b
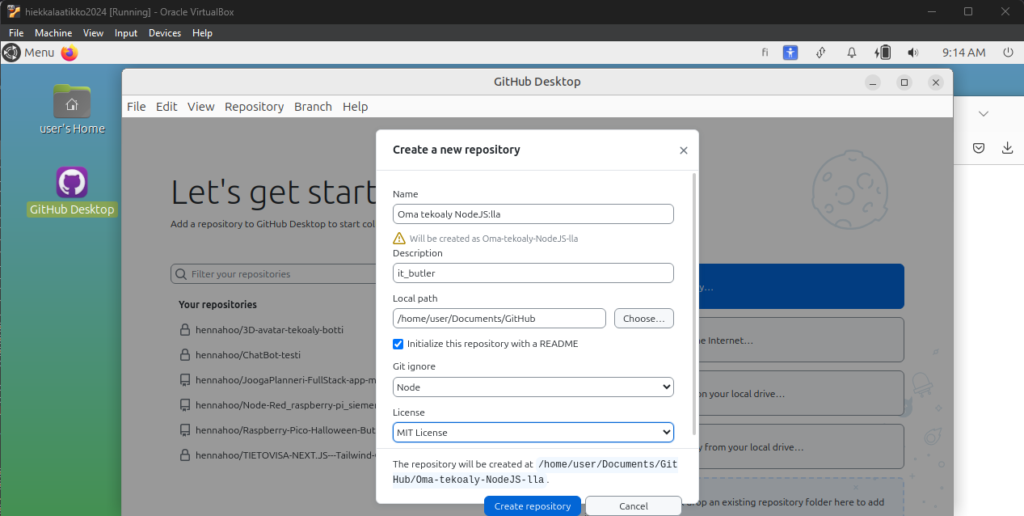
Aloitetaan oman WEB-käyttöliittymä sovelluksen tekeminen luomalla uusi GIT repositorio projektia varten:
(Github Desktop työkalun avulla se käy helposti. Aikaisemmassa postauksessa käytiin tätä läpi.)
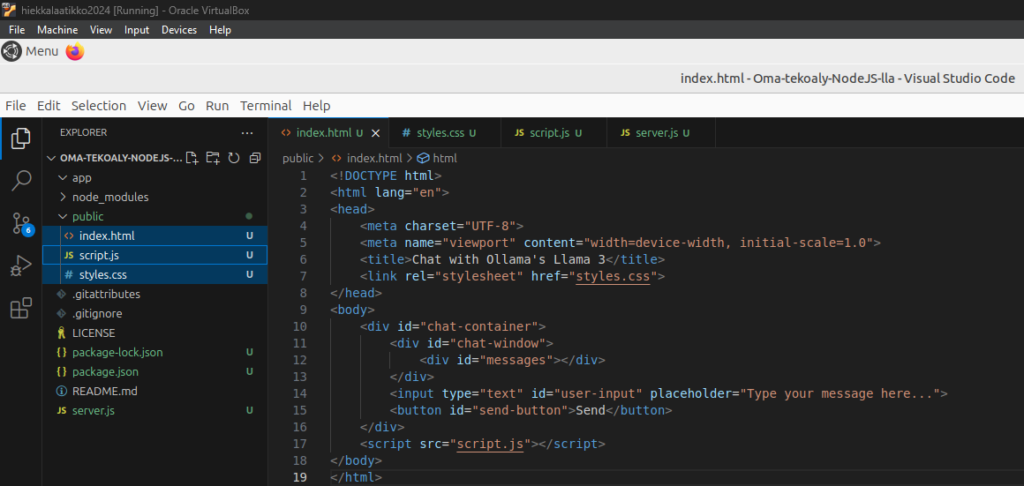
Luodaan projektin työkansioon uusi tiedosto index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Chat with Ollama's Llama 3</title>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<div id="chat-container">
<div id="chat-window">
<div id="messages"></div>
</div>
<input type="text" id="user-input" placeholder="Type your message here...">
<button id="send-button">Send</button>
</div>
<script src="script.js"></script>
</body>
</html>Uusi tyylitiedosto styles.css:
body {
font-family: Arial, sans-serif;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
background-color: #f0f0f0;
margin: 0;
}
#chat-container {
width: 400px;
border: 1px solid #ccc;
background-color: #fff;
border-radius: 8px;
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);
overflow: hidden;
}
#chat-window {
height: 300px;
padding: 10px;
overflow-y: auto;
border-bottom: 1px solid #ccc;
}
#messages {
display: flex;
flex-direction: column;
}
.message {
padding: 8px;
margin: 4px 0;
border-radius: 4px;
}
.user-message {
align-self: flex-end;
background-color: #007bff;
color: #fff;
}
.ai-message {
align-self: flex-start;
background-color: #e0e0e0;
color: #000;
}
#user-input {
width: calc(100% - 60px);
padding: 10px;
border: none;
border-radius: 0;
outline: none;
}
#send-button {
width: 60px;
padding: 10px;
border: none;
background-color: #007bff;
color: #fff;
cursor: pointer;
}Uusi JavaScript tiedosto script.js:
document.getElementById('send-button').addEventListener('click', sendMessage);
document.getElementById('user-input').addEventListener('keypress', function (e) {
if (e.key === 'Enter') {
sendMessage();
}
});
function sendMessage() {
const userInput = document.getElementById('user-input');
const messageText = userInput.value.trim();
if (messageText === '') return;
displayMessage(messageText, 'user-message');
userInput.value = '';
// Send the message to the local AI and get the response
getAIResponse(messageText).then(aiResponse => {
displayMessage(aiResponse, 'ai-message');
}).catch(error => {
console.error('Error:', error);
displayMessage('Sorry, something went wrong.', 'ai-message');
});
}
function displayMessage(text, className) {
const messageElement = document.createElement('div');
messageElement.textContent = text;
messageElement.className = `message ${className}`;
document.getElementById('messages').appendChild(messageElement);
document.getElementById('messages').scrollTop = document.getElementById('messages').scrollHeight;
}
async function getAIResponse(userMessage) {
// Example AJAX call to a local server interacting with Ollama Llama 3
const response = await fetch('http://localhost:5000/ollama', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ message: userMessage }),
});
if (!response.ok) {
throw new Error('Network response was not ok');
}
const data = await response.json();
return data.response; // Adjust this based on your server's response structure
}Asennetaan express backendi tälle projektille projektikansioon:
npm install express body-parserLuodaan uusi tiedosto server.js jonne kirjoitetaan backend koodi:
const express = require('express');
const bodyParser = require('body-parser');
const path = require('path');
const app = express();
const port = 5000;
// Middleware to parse JSON bodies
app.use(bodyParser.json());
// Serve the frontend HTML file
app.use(express.static(path.join(__dirname, 'public')));
// Define the POST endpoint to interact with the AI model
app.post('/ollama', async (req, res) => {
const userMessage = req.body.message;
// Replace this with actual interaction with Ollama's Llama 3
// This is a placeholder for demonstration purposes
const aiResponse = await getLlama3Response(userMessage);
res.json({ response: aiResponse });
});
// Placeholder function to simulate AI response
async function getLlama3Response(userMessage) {
// Replace this with actual API call to Ollama's Llama 3
return `Llama 3 says: ${userMessage}`;
}
// Start the server
app.listen(port, () => {
console.log(`Server running at http://localhost:${port}`);
});
Index.html, script.js ja styles.css tiedotot tulee olla /public kansiossa:
Nyt kun kaikki neljä tiedostoa on luotu, voidaan kokeilla lähteekö Express käyntiin, komentamalla:
node server.js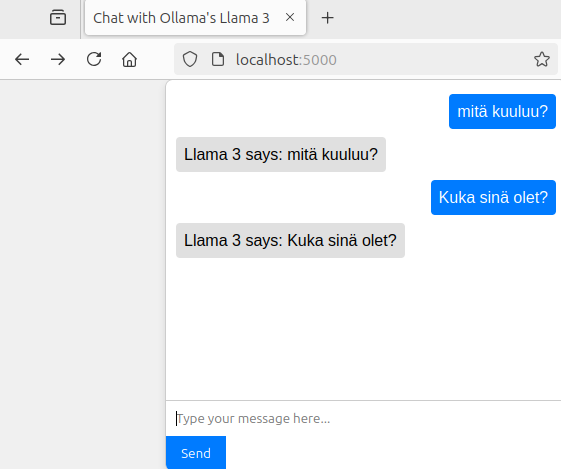
Hyvä, perusasiat ovat nyt kunnossa. Tekstikenttään voidaan kirjoittaa viesti, ja saadaan vastaus.
Tekoäly ei nyt vielä tuota kuitenkaan vastausta tälle web-sivulle.
Seuraavaksi muokataan koodia niin, että oikeasti keskustellaan Llama 3 tekoälyn kanssa ollama kirjaston avulla. Kirjasto täytyy ensin asentaa komentamalla terminaalissa:
npm install ollama
Sitten muokataan server.js tiedostoa:
const express = require('express');
const bodyParser = require('body-parser');
const path = require('path');
const { Ollama } = require('ollama'); // Correct import style
const app = express();
const port = 5000;
// Middleware to parse JSON bodies
app.use(bodyParser.json());
// Serve the frontend HTML file
app.use(express.static(path.join(__dirname, 'public')));
// Define the POST endpoint to interact with the AI model
app.post('/ollama', async (req, res) => {
const userMessage = req.body.message;
const ollama = new Ollama({ host: '127.0.0.1:11434' }); // Replace with your actual host
try {
// Send the user message to Ollama's Llama 3 and get the response
const response = await ollama.generate({
model: 'llama3.1', // Adjust the model as needed
prompt: userMessage,
stream: true
});
let aiResponse = '';
for await (const part of response) {
console.log(part); // Log the part object to see its structure
aiResponse += part.response; // Append the part response
}
res.json({ response: aiResponse });
} catch (error) {
console.error('Error querying Ollama:', error);
res.status(500).json({ error: 'Failed to get response from Ollama' });
}
});
// Start the server
app.listen(port, () => {
console.log(`Server running at http://localhost:${port}`);
});