Tekoälyn avulla on mahdollista luoda kuvia tekstistä varsin helposti ja se on nykyisin hyvin suosittua. On olemassa useita erilaisia web-palveluja, joiden avulla kuka vaan voi kokeilla tätä helposti selaimen avulla.
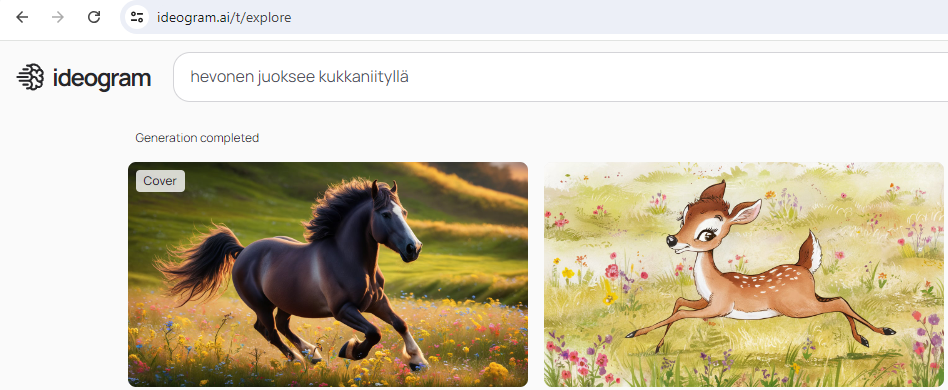
Ideogram on yksi tällainen verkkopalvelu, jonka avulla voit luoda kuvia pelkän tekstin avulla. Se käyttää tekoälyä ymmärtämään tekstikuvauksesi ja luo sen perusteella visuaalisia esityksiä. Aivan täysin tämä palvelu ei vielä suomen kieltä välttämättä ymmärrä, mutta kannattaa kokeilla. Palvelu on hyvin helppokäyttöinen, ja voit luoda kuvia ilmaiseksi seuraavasti:
- Rekisteröidy tai kirjaudu sisään:
- Mene Ideogramin verkkosivulle ja rekisteröidy tai kirjaudu sisään, jos sinulla on jo tili.
- Kirjoita tekstikuvaus:
- Syötä tekstikenttään haluamasi kuvaus siitä, millaisen kuvan haluat luoda. Voit esimerkiksi kirjoittaa “kissanpentu leikkimässä puutarhassa”.
- Generoi kuva:
- Paina luo kuva -painiketta. Tekoäly käsittelee tekstikuvauksen ja generoi sen perusteella kuvan.
- Tallenna ja jaa:
- Kun kuva on valmis, voit tallentaa sen laitteellesi tai jakaa sen suoraan sosiaalisen median alustoille.
Ideogramin avulla voit helposti ja nopeasti luoda kuvia tekstin perusteella ilman erityistä taitoa tai ohjelmistoja.
Tekoälyä voidaan hyödyntää kuvien generoimiseen tekstistä useilla eri tavoilla. Tämä prosessi tunnetaan nimellä tekstistä kuvaan (text-to-image) -generointi, ja se käyttää syväoppimisen ja neuroverkkojen menetelmiä. Tässä muutamia keskeisiä menetelmiä ja tekniikoita:
Generatiiviset Kilpailevat Verkot (Generative Adversarial Networks, GANs):
- StyleGAN: StyleGAN ja sen parannetut versiot (StyleGAN2, StyleGAN3) ovat suosittuja GAN-arkkitehtuureja, joita voidaan käyttää realististen kuvien generointiin. Ne voivat oppia tuottamaan kuvia, jotka noudattavat tiettyjä tekstikuvauksia.
- AttnGAN: AttnGAN on erikoistunut tekstistä kuvaan -generointiin käyttämällä huomioverkkotekniikkaa (attention mechanism), joka auttaa keskittymään tärkeisiin tekstin osiin kuvan luomisen aikana.
Diffuusiomallit:
- DALL-E ja DALL-E 2: Nämä OpenAImallit käyttävät diffuusiomallia, joka on koulutettu suuriin tekstin ja kuvan pareihin. DALL-E 2 pystyy luomaan korkealaatuisia ja monimutkaisia kuvia annettujen tekstikuvauksien perusteella.
- Stable Diffusion: Tämä malli käyttää myös diffuusiotekniikkaa ja tarjoaa avoimen lähdekoodin vaihtoehdon tekstistä kuvaan -generointiin. Stable Diffusion mahdollistaa laajan valikoiman sovelluksia ja on tunnettu sen joustavuudesta ja tehokkuudesta.
Transformeeripohjaiset mallit:
- CLIP + VQ-VAE-2: CLIP (Contrastive Language–Image Pretraining) yhdistettynä VQ-VAE-2 (Vector Quantized Variational AutoEncoder 2) on toinen lähestymistapa, jossa CLIP ymmärtää ja yhdistää tekstiä ja kuvia, kun taas VQ-VAE-2 generoi kuvia näiden tekstikuvausten perusteella.
Prosessi
Tekstin käsittely:
- Ensin teksti syötetään mallille, joka tulkitsee ja analysoi tekstin merkityksen ja kontekstin.
Ominaisuuksien poimiminen:
- Tekoälymalli poimii tärkeät piirteet tekstistä. Tämä voi sisältää objektien, ympäristöjen ja muiden yksityiskohtien tunnistamista tekstin perusteella.
Kuvan generointi:
- Generatiivinen malli luo kuvan, joka vastaa mahdollisimman hyvin annettua tekstikuvausta. Tämä vaihe voi sisältää useita iterointeja, joissa malli hienosäätää kuvaa.
Kuvan tarkennus:
- Joissakin menetelmissä, kuten GAN-pohjaisissa malleissa, toinen verkko (kriitikko) arvioi kuvan laatua ja ohjaa generatiivista verkkoa parantamaan tuotettua kuvaa.
Esimerkkejä Sovelluksista
- Luova taide: Tekoäly voi luoda taidetta annettujen tekstikuvausten perusteella.
- Elokuva- ja peliteollisuus: Konseptitaiteen ja hahmojen luonnin nopeuttaminen.
- Markkinointi ja mainonta: Visuaalisen sisällön nopea tuottaminen mainoskampanjoita varten.
- Koulutus ja tutkimus: Visuaalisten materiaalien luominen opetustarkoituksiin.
Teknologia on edistynyt huomattavasti ja tarjoaa yhä realistisempia ja laadukkaampia kuvia, jotka vastaavat monimutkaisia tekstikuvauksia. Tämä tekee tekstistä kuvaan -generoinnista hyödyllisen työkalun monilla aloilla.